by Ben Wicks, Head of Research Innovation, and Mark Ainsworth, Head of Data Insights and Analysis, both Schroders.
Modern fund managers are faced with a flood of data that can be analysed in ways unheard of 30 years ago. If they want to stay ahead of the game, they need to channel this deluge and harness its power to generate alpha in new ways.
There was a time when fund managers only had a limited supply of information to deal with – there were companies’ report and accounts, sell-side research and industry data. Processing power was limited to Excel spreadsheets, but that was all which was required to do the work and make the appropriate judgements about how to apply the data.
Things have changed significantly since, particularly in the last three or four years following exponential growth in the amount of information now confronting the investment industry. These developments pose disruptive challenges at the same time as providing a major opportunity for adaptive, well-structured organisations.
There is a vast amount of previously unavailable data becoming exploitable for stockpicking. Examples are too many to mention, but include: web-traffic data, smartphone-related data, open source government data, massive consumer survey data, mapping data and weather data. The industry really hasn’t moved on and learnt to handle information for itself in a way that others have.
We would argue it would be negligent to ignore these alternative sources of data given the potential alpha to be found within.
Channelling the data deluge
So what is driving this data deluge? Firstly and primarily, it is the ever-pervasive process of digitalisation that is happening. Transactions between consumers and businesses, and from businesses to businesses, are increasingly digitised and visible for subsequent analysis at an aggregated and abstracted level.
Secondly, it is the growing transparency demanded by public markets, especially in the West, but also increasingly across emerging markets. Government to business interactions are subject to increasing disclosure, for example. Thirdly, the increase in computing power is playing a key role as costs for storing and processing the data continue to tumble.
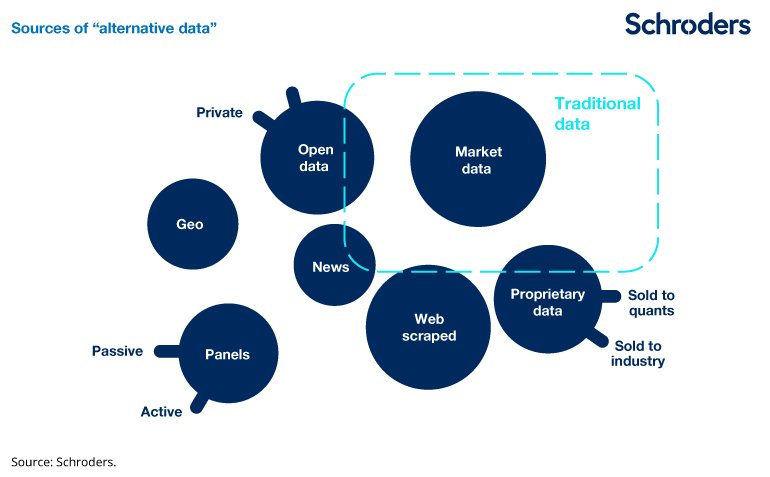
From the perspective of fund managers, it’s no longer sufficient to manage this data without taking a systematic approach and bringing in coding and data engineering skills to create a “Big Data” analytics capability. In our opinion fund managers which invest properly in this area will benefit from an “information edge”.
Far from creating a level playing field, where more readily available information simply leads to greater market efficiency, this information revolution is having the opposite effect.
To be effective, a capability will go beyond that currently available market data, to discover new sources of alternative information that the market may not be collectively aware of. Secondly, it will need to find a way of making sense of the data and serve up insights for fund managers to apply their judgement to. This is not about replacing managers, it’s about enabling them, which is why working in partnership needs to be the third key plank of any capability. Without understanding the questions that the investment teams are seeking to answer, it won’t be possible to know where to apply the data science.
Here at Schroders we’ve set up the Data Insights Unit (DIU) which employs over 20 data scientists from a variety of backgrounds and industries. We have delivered concrete evidence of successfully using Big Data in support of fundamental research.
Practical applications
One early such example related to the merger of UK gaming groups Ladbrokes and Coral. At the time the merger was announced Schroders had a significant holding in Ladbrokes. The key question for the investment team was how many stores would need to be divested for the competition authorities to allow the merger to continue. Initial views from sell-side analysts were between 100 and 1,800 stores out of a combined estate of 4,000 – clearly insufficiently precise for an analyst to recommend to a fund manager what the merger might mean for Ladbrokes.
However, working in collaboration with the investment desk the DIU was able to identify the correct data source which might hold some answers. It was then our job to compute the data to establish how the competition rules might play out for each individual betting shop. That involved calculating the distance of every store to every other store – through 70 million permutations, which is not something you can do on an Excel spreadsheet – and over the course of the day we came to the conclusion that 400 stores would need to be sold. A year later the regulator came out with their initial judgement for the disposal of 350 and 400 stores.
Some of the very large datasets available, such as large samples of web-browsing histories from around the world, would be impossible to combine with legacy analytics technology. They demand the use of newer cloud computing techniques and more agile data querying methods. Sometimes this data can be text, rather than numbers and there is significant demand from our fund managers to bring unstructured, very obtuse data to heal. This might include an analysis of company patents, which are last on their reading list given there are hundreds of thousands issued in large Western countries in each year alone.
Patent data is extremely messy, yet quite important to understand given that companies will typically spend 5% to 10% of their sales on research and development (R&D). Semantic analysis is required to compare the text in every patent with every other patent in order to group them by type, which is relatively quick to do with cloud computing.
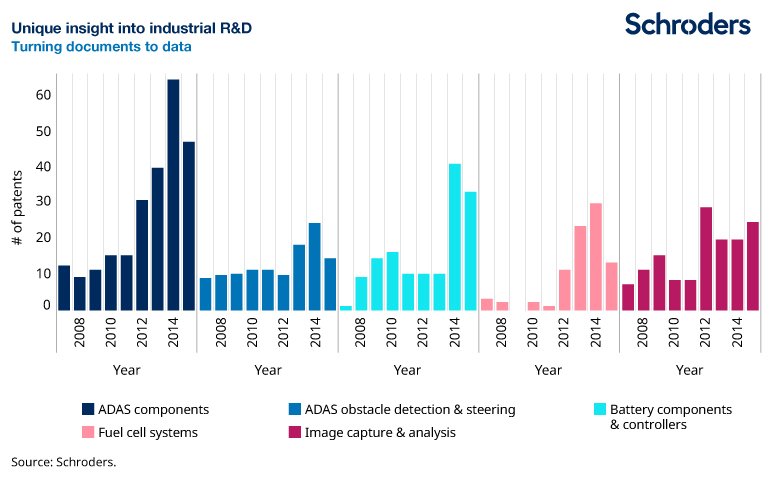
The graphic below illustrates the various type of patents launched by an auto manufacturer since 2008 covering five “buckets”, ranging from fuel cell systems to advanced driver assistance systems (ADAS). This cannot be achieved through simple search as raw patents are complex and poorly indexed documents. While not shown here, the real power is comparing this data across a number of auto manufacturers to help identify where they’re focusing their R&D efforts going forward.
Advantages of scale
Other industries have been faster to adapt to this new world than finance which has come to heavily rely on the information provided via their terminals. Fund managers have not learnt to handle things for themselves in a way that the pharmaceuticals sector has, for example, and this is why any new “Big Data” analytics capability will need to draw on expertise outside of the industry.
This should also have the benefit of bringing in new ideas and innovative ways of doing things, plus a network effect – connecting people from diverse industries makes it easier to identify key hires.
In our opinion, the large traditional fund management firms have a significant advantage over both smaller firms and hedge funds when using Big Data to support fundamental research. This is because they already have a large body of well-informed analysts, meaning hypothesis-generation can be better informed and more reliable. Understanding the key question that matters to a particular company at a particular time is complex, and can only really be framed by an analyst with intimate fundamental knowledge of the company or industry. The combination of powerful question-generation with powerful data-exploitation to answer the question is stronger than either aspect alone.
Using Big Data to support fundamental research should increase transparency of an investment process, in our opinion. It should be easier to track whether a hypothesis is failing or working if there is more data available to measure and base the conviction upon.
Certainly there are risks, such as attributing too much certainty to insights from innovative datasets that are not necessarily fully understood. Very large and alternative datasets are often less precise or clean than traditional “market data” because the information may be emanating from organisations or facilities whose primary purpose is not the provision of clean, holistic, data to stockmarket participants. But when appropriate confidence intervals are applied, then the benefit of having additional information to consider is always additive.
Organisations that successfully adapt to this data-heavy world will have a mindset of innovation and collaboration. They will also be large enough and have sufficient technological prowess to compete. Those that do evolve, and that remain agile enough to avoid the pitfalls while embracing continuous change, will be in the best position to offer their clients sustainably differentiated returns.
This article has first been published on schroders.com.
* DE: Die ergänzenden Inhalte können KI-generiert sein. EN: The additional content may be AI-generated.